

Stable Diffusion ist das AI-Image-Model, das hinter vielen KI- oder AI-Bildgeneratoren steckt. Wer zu Hause für sich selbst Bilder generieren möchte, ist sicherlich schon auf Midjourney gestoßen. Über Midjourney habe ich bereits einen Artikel verfasst. Wer allerdings eine leistungsstarke NVIDIA-Grafikkarte zu Hause besitzt, ist in der Lage, selbst Bilder zu generieren. Wie das Ganze funktioniert, erkläre ich in diesem Artikel.
Es ist allerdings zu beachten, dass die Anwendung nicht so einfach ist wie Midjourney. Man sollte sich auf jeden Fall mit Docker und/oder Linux und der Kommandozeile auskennen. Allerdings sind keine Programmierkenntnisse erforderlich.
Zur genauen Einrichtung, wie man Stable Diffusion zu Hause aufsetzt, werde ich später noch einen Artikel verfassen. Sollte dieser bereits vorhanden sein, findet ihr ihn verlinkt am Ende dieses Artikels.
Was wird benötigt?
Zuallererst benötigt man eine leistungsstarke NVIDIA-Grafikkarte. Diese sollte mindestens eine 2000er Serie, idealerweise eine 3000er oder noch besser eine 4000er Serie sein. Ich habe es auf einer Nvidia 4080 getestet und es funktioniert wunderbar.
Wer allerdings eine AMD-Karte oder eine weniger leistungsfähige Grafikkarte besitzt oder weniger als 8GB (besser 12 oder mehr) VRAM, also Grafikkartenspeicher, hat, für den wird es nicht funktionieren.
Zum Beispiel hat mein letzter Command folgendermaßen VRAM benötigt:
Time taken: 14.27s
Torch active/reserved: 3450/8284 MiB, Sys VRAM: 8792/16074 MiB (54.7%)Je größer man das Bild skaliert oder andere Commands verwendet, desto mehr VRAM wird benötigt.
Für die Generierung gibt es praktische WebGuis, die man installieren kann.
Zu den prominentesten Projekten gehören:
 invoke-ai
invoke-aiMit einer ausgezeichneten Dokumentation, diese ist hier zu finden:
 mauwii
mauwii
und das prominenteste: (80k Sterne auf Github)
AUTOMATIC1111Zusammenfassend:
- Grafikkarte > Nvidia 2060, je mehr VRAM desto besser, AMD funktioniert nicht.
- WebUI Toolkit installieren. Siehe oben, Anleitungen findet man auf den zugehörigen Webseiten.
Wie erstelle ich Bilder?
Sobald man das WebGui erstellt hat, kann man auch gleich loslegen und Bilder erstellen. Doch wenn man einfach das vorhandene Stable Diffusion Model nutzt, ist es sehr schwierig, an die Qualität heranzukommen, die zum Beispiel Midjourney bietet.
Um eine bessere Qualität zu erzielen, lädt man sich neue Modelle aus dem Internet herunter, die optimiert wurden und eine bessere Qualität liefern. Diese basieren meistens noch auf Stable Diffusion.
Diese sind herunterladbar und haben die Dateiendung "*.ckpt", üblicherweise wird aber die ".safetensors"-Datei heruntergeladen.
Zum Beispiel gibt es folgendes Modell zum Herunterladen:

auch auf :
Findet man zum Beispiel verschiedenste unterschiedliche Models, LoRA (dies sind kleine Erweiterungen welche den Bildstil beeinflussen) wie auch zum Beispiel Negative Prompts.
Der populärste ist der sogenannte Chilloutmix auf Civatai. Mit diesem werde ich im Folgenden einige Beispielbilder erstellen und euch erklären, wie ihr zu den besten Ergebnissen kommt.
Docker
Wer sich mit Docker auskennt dem sei folgendes Projekt auf Github empfohlen:
AbdBarhoChilloutmix Test
Diesen findet ihr hier zum herunterladen: https://civitai.com/models/6424/chilloutmix
Installieren könnt ihr das Model indem ihr einfach die *.safetensors herunterlädt.
Eine Übersicht über die WebGui:
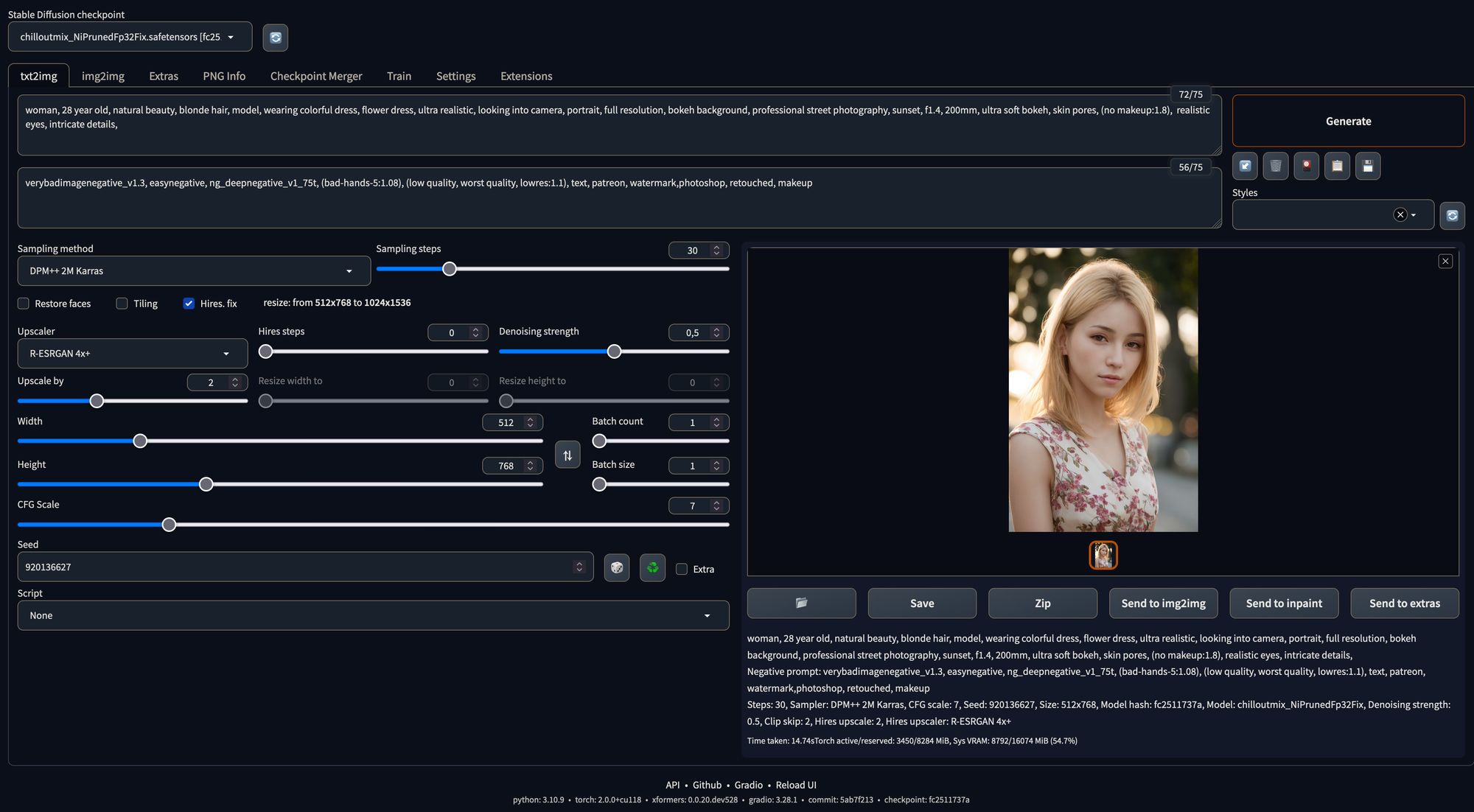
Das Bild welches daraus generiert worden ist:

Die Einstellungen für obiges Bild:
positive prompt:
woman, 28 year old, natural beauty, blonde hair, model, wearing colorful dress, flower dress, ultra realistic, looking into camera, portrait, full resolution, bokeh background, professional street photography, sunset, f1.4, 200mm, ultra soft bokeh, skin pores, (no makeup:1.8), realistic eyes, intricate details,
negative prompt:
verybadimagenegative_v1.3, easynegative, ng_deepnegative_v1_75t, (bad-hands-5:1.08), (low quality, worst quality, lowres:1.1), text, patreon, watermark,photoshop, retouched, makeup
DPM++ 2M Karras
30 Steps
Hires Fix: Denoising 0.5
Upsacler RealESRGAN 4x+Ich werde jetzt im Detail die einzelnen Einstellungen versuchen zu erklären und wie sie das Bild beeinflussen.
Stable Diffusion Checkpoint
Hier könnt ihr das unterschiedliche Modell auswählen. Neue könnt ihr auf verschiedenen Webseiten herunterladen. Die populärsten Webseiten habe ich oben schon verlinkt.
Weiter unten gibt es die unterschiedlichen Tabs. Ich werde erstmal auf das "text2img"-Tab eingehen, da hier die meiste Magie passiert.
Textprompt
Als Erstes gibt man seinen Textprompt ein. Hier habe ich Folgendes eingegeben:
woman, 28 year old, natural beauty, blonde hair, model, wearing colorful dress, flower dress, ultra realistic, looking into camera, portrait, full resolution, bokeh background, professional street photography, sunset, f1.4, 200mm, ultra soft bokeh, skin pores, (no makeup:1.8), realistic eyes, intricate details,Meine Intention war, ein Portrait mit einem Bokeh im Hintergrund zu generieren. Deswegen habe ich auch passende Objektiveinstellungen angegeben, die ein Fotograf zum Beispiel für ein solches Bild verwenden würde. "Skin Pores" habe ich angegeben, damit man Details der Haut erkennt. Ich könnte dies noch ein bisschen stärker gewichten. Gewichten kann man übrigens folgendermaßen: (no makeup:1.8) Den Begriff einfach in Klammern schreiben und eine höhere Gewichtung angeben.
Negativ Prompt
Dann gibt es noch den Negativ Prompt, der mindestens genauso wichtig ist wie der Positiv Prompt. Bei mir sieht er momentan so aus:
verybadimagenegative_v1.3, easynegative, ng_deepnegative_v1_75t, (bad-hands-5:1.08), (low quality, worst quality, lowres:1.1), text, patreon, watermark,photoshop, retouched, makeupDamit verybadimagenegative_v1.3, easynegative oder ng_deepnegative_v1_75t funktioniert, muss die entsprechende Datei heruntergeladen werden. Diese findet man zum Beispiel auf Civatai.
Hires Fix
Als Erstes erstelle ich meistens ein Foto ohne den Haken bei "Hires, Fix".
Sampling Steps

Bei manchen Models machen die Sampling Steps nicht viel Unterschied. Falls die Option "Hires, fix" aktiviert ist sollten die Sampling Steps nicht zu hoch gestellt werden.
Das obige Beispiel ist vielleicht nicht das beste um den Einfluss von Sampling Steps zu zeigen.
Sampling Method
Hier wählt man den Sampler aus, welcher genutzt werden soll. Hier eine kleine Übersicht wie der Sampler das Bild beeinflusst:

Der häufigst empfohlene Sampler ist der DPM++ 2M Karras.
Resolution
Als Auflösung muss eine Auflösung gewählt werden mit der auch das Model trainiert worden ist. Dies ist meistens 512x512 oder 512x768.
Batch Count
Hier wird eingestellt wieviel Batches erstellt werden soll.
Batch Size
Wieviele Bilder in einem Batch generiert werden sollen.
Seed
Als Seed wählt man einen Random Seed, ausser man ist vielleicht mit einem Seed zufrieden und will diesen minimal ändern.
Restore Faces
Diese Option sollte je nach Model deaktiviert werden. Meistens sollte die Option auch deaktiviert werden wenn mit "Hires, fix" Das Bild geupscaled wird.
Andere Models









If you press this button it will load Disqus-Comments. More on Disqus Privacy: Link